 Regard sur l’image
Regard sur l’image
La théorie de l’échantillonnage serait-elle la faille de la théorie de l’information ?
Prologue
Un signal analogique est par essence continu, il n’est donc ni décomposé ni découpé. L’impossibilité physique de faire des mesures en continu sur un signal analogique est la conséquence de ses deux caractéristiques.
En admettant qu’il soit possible d’évaluer un signal même à une cadence de toutes les femtosecondes [1], voir, toutes les attoscecondes [2] nous serions dans l’impossibilité de restituer la spécificité d’un signal analogique : sa continuité. L’essence de la continuité est d’être insécable. Par ailleurs, si, toutefois, ce rythme de quantification était accessible, la quantité de données collectées serait totalement ingérable même en huit bits..

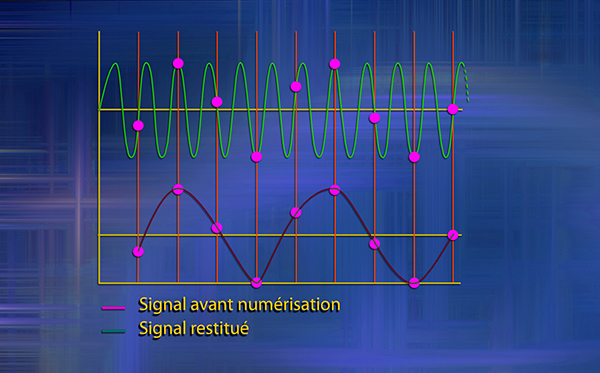
De cette impossibilité provient un des pré-requis. Pour évaluer, quantifier un phénomène, un intervalle entre chaque mesure est impératif. Comme le schéma intitulé « conséquence d’un sous-échantillonnage » ainsi que la vidéo sur l’erreur d’échantillonnage le montrent, on comprendra donc que selon l’ampleur de cet intervalle le résultat obtenu risque d’être totalement différent. Ainsi, plus le temps écoulé entre chaque mesure sera important, plus les différences d’intensité du signal seront écrêtées.
erreur d'échantillonnage from BERNARD Hervé (rvb) on Vimeo.
L’autre pré-requis à l’échantillonnage et de la quantification est, l’invention par Descartes de l’espace orthonormé. Sans cet espace et ses deux axes de mesure : le temps et la quantité par unité de temps, l’échantillonnage est impossible.
1 La théorie de l’information
En numérique, l’“information” n’existe pas sans échantillonnage. C’est-à-dire l’action de prélever une parcelle de l’objet à évaluer à une cadence régulière. C’est l’échantillonnage qui crée l’information. En fait, dans la théorie de l’information, une information est définie par la mesure d’une quantité à un intervalle, une périodicité donnée.
Pour la théorie de l’information, une chose, un évènement est une information à partir de l’instant où on lui porte un intérêt. Il n’en faut pas plus. Dans le cadre de cette théorie, la question de savoir si porter un intérêt à quelque chose rend cette chose pertinente n’est pas judicieuse. Par conséquent, un rien peut-être de l’information et même trois fois rien. La seule nécessité, l’unique condition est que ce rien soit mesurable, quantifiable. Hors, on peut tout ou quasiment tout soumettre à la statistique. Tout est mesurable à intervalle régulier. Ici, mesurer : c’est généralement évaluer des quantités.
Du point de vue de la théorie de l’information la taille (longueur, ou diamètre) d’un radis, son rapport longueur-diamètre, son poids, la densité de son rose et son blanc ou encore leur proportion dans la surface extérieure peuvent être mesurés, ce sont donc des informations...
Quant à l’intervalle, la périodicité, ils définiront essentiellement une surface (capteur d’appareil photo...), une durée (intervalle temporel séparant la consommation d’un produit...) ou encore un intervalle quantitatif (1/3 ou 1/5...). Ce dernier est, en fait, une variante de l’intervalle temporel. En fait, un échantillonnage est toujours biaisé par sa périodicité et par la mesure choisie. Ce biais rend caduque cette prétention à l’exactitude mathématique, scientifique.
En fait la théorie de l’information ne cherche pas à informer. Elle ne cherche qu’à collationner des échantillons qui font l’objet d’une évaluation. C’est-à-dire d’opérations mathématiques. Si la théorie de l’information est une théorie de quelque chose, c’est une théorie de la mesure, de la caractérisation mathématique. Ces caractérisations étant des chiffres, elles sont donc aisément transmissibles. Vérifier la pertinence du contenu de la transmission est hors-sujet c’est en ce sens que son nom est trompeur. La tromperie de l’expression réside dans sa formulation : théorie de l’information. Contrairement à ce que son nom laisse croire, faire une évaluation sémantique des données transmises n’a jamais été l’objet de cette théorie.
Le résultat caricatural ressemble un peu à cela. [3] Imaginez que dans une école, pour évaluer l’ensemble des trente élèves d’une classe, on décide, en raison des contraintes budgétaires ou pour tout autre principe, on décide de ne plus corriger les trente copies chaque semaine. Cependant, simultanément, on veut conserver les notes et une cadence hebdomadaire (première variable aléatoire) afin de maintenir la pression sur les élèves ou afin de les stimuler (question d’interprétation). Donc, il va falloir inventer un système d’évaluation hebdomadaire.
Donc, pour des raisons budgétaires, certaines semaines, un élève sur trois sera noté (première variable aléatoire), tandis que d’autres semaines, un élève sur dix sera noté (variante de la première variable aléatoire) nécessaire pour répondre aux exigences budgétaires. Ensuite, tous les élèves qui ne sont pas notés, reçoivent la note de l’un des trois élèves notés ou de l’un des dix selon (seconde variable aléatoire). Quant aux critères d’application, on peut imaginer que le premier tiers des élèves reçoivent la note du premier élève, le second tiers, la note du second et le dernier tiers, la note du troisième. Comment déterminer ces trois tiers, c’est-à-dire la troisième variable ? Par le placement des élèves dans la classe le jour de l’interrogation, par leur placement, le jour de la remise des notes ou en prenant l’ordre alphabétique et en le divisant par trois ou encore en divisant la classe par trois et en prenant comme référence l’ordre de classement de la copie précédente. Bien entendu, pour les semaines où un élève sur 10 est noté on appliquera les mêmes critères. Voilà ce que peut donner une application à peine caricaturale du traitement statistique de la théorie de l’information.
Cette caricature est là pour montrer que l’évaluation de cette fréquence d’échantillonnage est soumise a bien des paramètres et peut facilement être distordue, la répartition en fonction du classement est un exemple de distorsion maximale. C’est pourquoi, il faut se méfier de la statistique et surtout ne pas la prendre pour argent comptant.

2 Une théorie de l’information, réellement ?
Cependant, Shannon n’a jamais prétendu inventer une théorie de l’information. En effet, la première fois qu’il fait mention de son projet dans "A mathématical theory of cryptography" [4] il parle d’une théorie de la transmission de l’information. Il dira au début de son article :« Le problème fondamental de la communication est de reproduire exactement ou approximativement un message donné d’un point à un autre. » Par ailleurs, pour Shannon, une information est ce qui permet de lever une incertitude ce qui n’a rien à voir avec le concept d’information tel qu’il est entendu par le vocable théorie de l’information. Ultérieurement, cette théorie deviendra une théorie du stockage car du point de vue de Shannon, le stockage est une transmission différée qui pose les mêmes problèmes que la transmission : volume, perte de données...
Nous ignorons qui, de ses successeurs, de la direction des laboratoires Bell ou des vulgarisateurs, ont affublé la théorie de Shannon du nom de théorie de l’information ou laissé ce glissement se faire. Il s’est d’ailleurs probablement fait progressivement. Toujours est-il qu’ils ont vaincu la sémantique avec cette superbe dénomination qui a conduit notamment, les journalistes à confondre statistique et analyse. Cette dernière étant la réelle information. Cette dénomination laisse croire, sous-entend qu’une information ne peut être que chiffrée.
D’un point de vue sémantique, cette torsion de l’ambition de Shannon, ce nom de théorie de l’information est un chef d’œuvre de marketing. Ce terme désigne une coquille vide. En fait de société de l’information, nous sommes en présence d’une société de la circulation des données chiffrées, des statistiques. L’information n’est vraiment pas le sujet. Pour mémoire, l’information est l’action de mettre en forme (première occurrence de cette acceptation en 1495), de donner une forme à quelque chose. C’est aussi un renseignement que l’on obtient sur quelqu’un (première occurrence de cette acceptation en 1360) enfin, c’est une enquête en matière criminelle (première occurrence de cette acceptation en 1274). Cette théorie de la quantification a été conçue pour transmettre des données, ensuite, elle a servi à stocker les dites données.
Pour continuer dans la sémantique, cette soi-disante théorie de l’information utilise des machines à calculer, le français des années 1970 n’avait pas tort, ce ne sont que des calculateurs. Ces machines ne sont en rien des ordinateurs. L’ordinateur est celui qui institue quelque chose (première occurrence de cette acceptation en 1491) ou encore, celui qui met en ordre qui règle (première occurrence de cette acceptation en 1956). Le mot ordinateur provient du mot latin ordinatum qui lui-même provient du verbe ordinaire dans le sens de ordonner, mettre de l’ordre. Rien à voir avec de l’information.
3 Démonstration : le PageRank [5]
Le PageRank est un algorithme qui, selon Google, détermine la pertinence d’une réponse fournie à un utilisateur suite à une question. En fait, cet algorithme ne fournit qu’une seule information : à propos du thème en question, cette page est la plus lue. Peu importe que les lecteurs soient profondément insatisfaits à l’issue de cette lecture soit par la faiblesse de son argumentaire, soit parce que cette page ne correspond aucunement à l’information recherchée parce que Google bute sur une homonymie... Certes, la réponse fournie est notamment pondérée par nos requêtes précédentes et les cookies que nous déposons et/ou que Google enregistrent.
En fait, plus une page est vue, plus son PageRank augmente et plus celui-ci s’accroît plus il augmente. Nous sommes alors dans une spirale ascendante, dans un cercle “vertueux” ce qui pourrait être positif si le cercle vertueux ne question ne provoquait pas simultanément la naissance du cercle infernal : moins on est référencé, moins on est référencé... C’est la spirale descendante, le cercle infernal.
Pourtant, ce n’est pas parce qu’une page à un faible référencement qu’elle n’est pas pertinente et même le faible nombre de liens qui renvoient vers elle n’est pas le signe d’une pertinence insuffisante. Cela peut l’être mais, cela peut-être, aussi, l’indication que cette page vient d’être publiée —ce dernier critère est d’ailleurs compensé par une sur-évaluation de la valeur des pages les plus récentes. Cela peut simplement être l’indicateur du manque de curiosité du public pour cette thématique ou encore d’un traitement du sujet beaucoup trop ardu pour la majorité des internautes. Dans ce dernier cas : le temps réduit voir infinitésimale passé sur le site, on est en présence d’une pondération négative.
Tous ces critères de corrections des paramètres de classement sont construits autour de plusieurs présupposés :
– l’intérêt de la majorité pour une page est un signe de qualité, tout le monde cherche la même chose, avec le même niveau d’exigence ;
– une photo et un texte de quelques lignes n’ont pas le même poids, pour Google, la première a plus de poids que le second ;
– une publication récente a plus de poids qu’une publication ancienne, pourtant si la page la plus ancienne a été rédigée par un membre du Collège de France, sa pertinence sera probablement supérieure à celle d’une page traitant du même thème est rédigée par vous ou moi...
4 Les statistiques et la théorie des ensembles
Les statistiques sont intimement liées à la théorie des ensembles et selon le choix de l’ensemble référentiel. Leurs résultats peut varier de manière très substantiel comme le montre le cas d’école de l’évolution du vote du FN depuis 2000, voire depuis une période plus longue. Selon le référentiel : nombre d’électeurs inscrits, nombre de suffrages exprimés ou encore en tenant compte des bulletins nuls ou blancs, ce score peut être constant, décroissant ou croissant.
5 Sémiologie sémiotique ou sémantique
En fait, la sémiotique [6] a pris forme à une période où la tendance était au découpage du savoir tout comme, à cette même période, la production, avec le fordisme, a vu une parcellisation des tâches sur la chaîne de production encore plus grande que celle du taylorisme.
Comme nous venons de le voir, la théorie de l’échantillonnage repose sur cette parcellisation. Un parallèle est possible entre la stratégie de découpage des langues par la sémiologie en des éléments de plus en plus petits et la tendance de l’échantillonnage, théorie à la base de la statistique, à découper. Même Freud, en 1901, est déjà atteint par ce symptôme de la parcellisation lorsqu’il affirme, dans la Psychopathologie de la vie quotidienne : « On pourrait se donner pour tâche de décomposer, en se plaçant à ce point de vue, les mythes relatifs au paradis et au péché originel, à Dieu, au mal et au bien, à l’immortalité, etc. et de traduire la métaphysique en métapsychologie. » [7]
Nous avons confondu théorie de l’information et théorie de la transmission ou encore sémiologie-sémiotique et sémantique. Dans ces deux théories (transmission et sémiologie-sémiotique), le sens n’est pas le sujet. Cette soi-disante théorie de l’information ne met rien en forme, elle se contente de découper, de hacher menu et la sémiologie fait de même.
La théorie de l’information a été élaborée afin de faciliter la transmission des données, en cela, elle est plus l’héritière du morse que de la sémantique et, dans le domaine de la transmission, son efficacité est indéniable. Le monde numérique n’existerait pas sans elle. Ce que nous contestons, c’est son nom. Elle devrait se nommer théorie de la transmission comme son père l’avait nommée. D’une certaine manière, la théorie de l’information est à l’information ce que la sémiologie-sémiotique est à la sémantique. C’est-à-dire une théorie du code et non du sens. Si théorie de l’information il y a, il vaudrait mieux aller voir du côté de McLuhan.
© Hervé Bernard 2016-2017
_________________________________________________________________________________________
Regard sur l’image,
un ouvrage sur les liens entre l’image et le réel.
350 pages, 150 illustrations, impression couleur, format : 21 x 28 cm,
France Métropolitaine : prix net 47,50 € TTC frais d’expédition inclus,
Tarif pour la CEE et la Suisse 52,00 € , dont frais d’expédition 6,98 €,
EAN 13 ou ISBN 9 78953 66590 12,
Pour acquérir cet ouvrage dans la boutique
_________________________________________________________________________________________
- L’algorithme, un point de vue sur le monde V3
voir aussi - Ne confondons pas échantillonnage et marchandage ! (1) ou les enjeux de la statistique dans la fabrication d’une image.
- La statistique, une forme de cadre, d’image
Algorithmes et fabrication des images Entretien en deux parties avec Frédéric Guichard, directeur scientifique de DXO, par Jean-Louis Poitevin, voir le lien à la fin de l’article.